
Why anomaly detection is not binary classification
Anomaly detection refers to the problem of finding patterns in data that do not
conform to expected behavior.
Like a fish swimming upstream, the mouse befriending the cat and the rich giving to the poor.
But also like
- the malicious user in your organization
- the defecting engine you just manufactured
- the fraudulent credit card transaction you just processed
- the unreasonable network traffic on your servers
- …
It seems that Anomaly Detection amounts to all but separate the good from the bad. And in fact, it is. So why not dig up the good old binary classification?
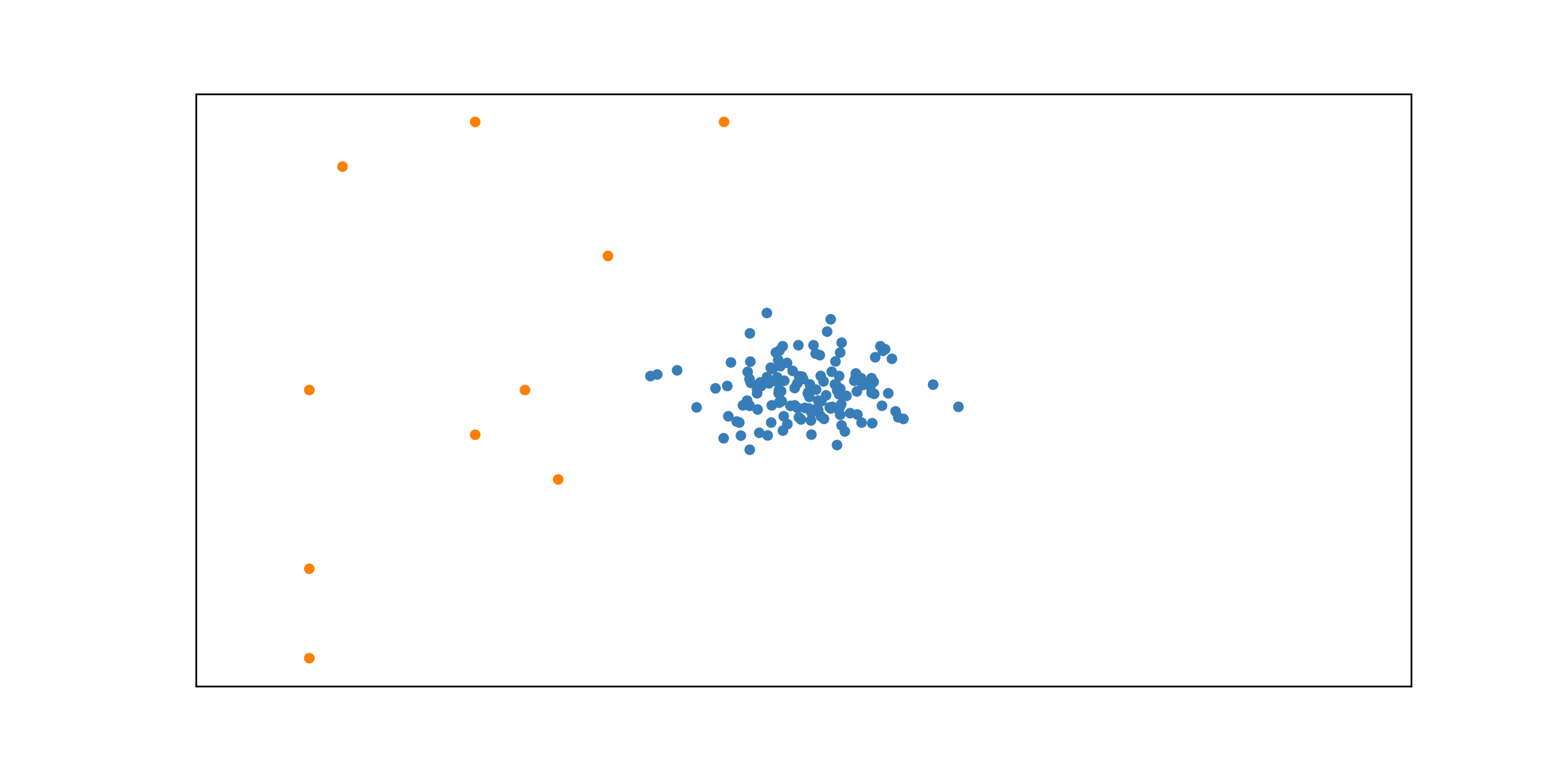
What the heck, let’s try and get started with those engines. We manufacture a few hundred engines, but, hey, after too many hours of work we are tired and some of them do not seem to work really well.
After intensive testing these are the unforgiving results: 10 engines are faulty! We draw the engines on a 2D map (let’s suppose to describe an engine with two features) coloring the faulty ones with orange.
Now we really do not want to spend that much time testing out all those engines and we invoke the magic power of AI to solve the problem. We put all that blue and orange dots in a table a fed it to a binary classification model (we are going to use an SVM classifier for this example). We do the things properly—the machine learning way: we set up a validation scheme to tune our hyper-params we choose a suitable metric for unbalanced classification and all of that. After crunching the numbers and we get this:
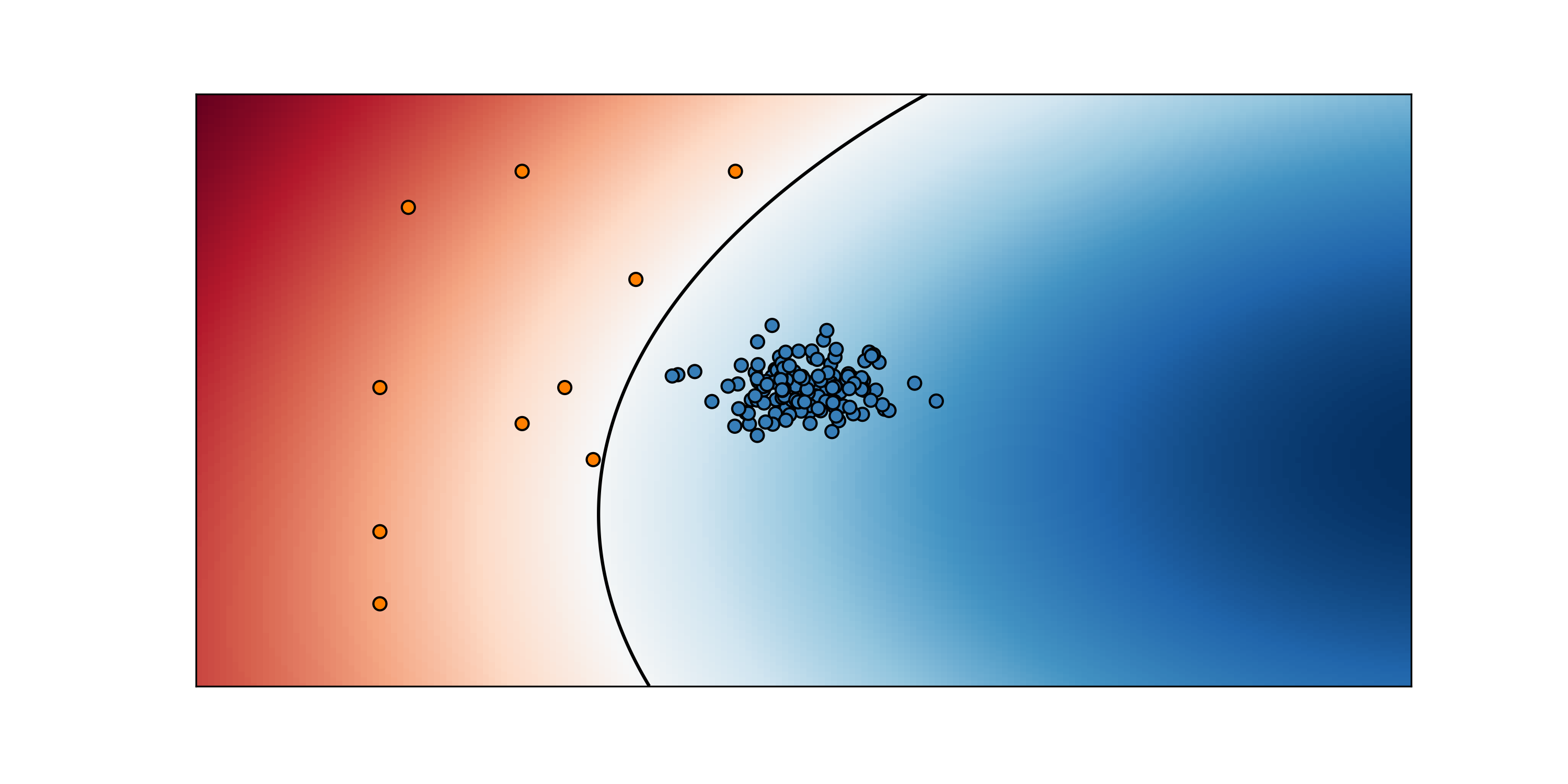
Are we satisfied? Well, it seems we are doing good with our anomalies so far. Let’s go and make more engines! We work hard and get new engines done. Well were even more carefully this time, but some are defective still. Let’s put them on the map and see how is our classifier doing.
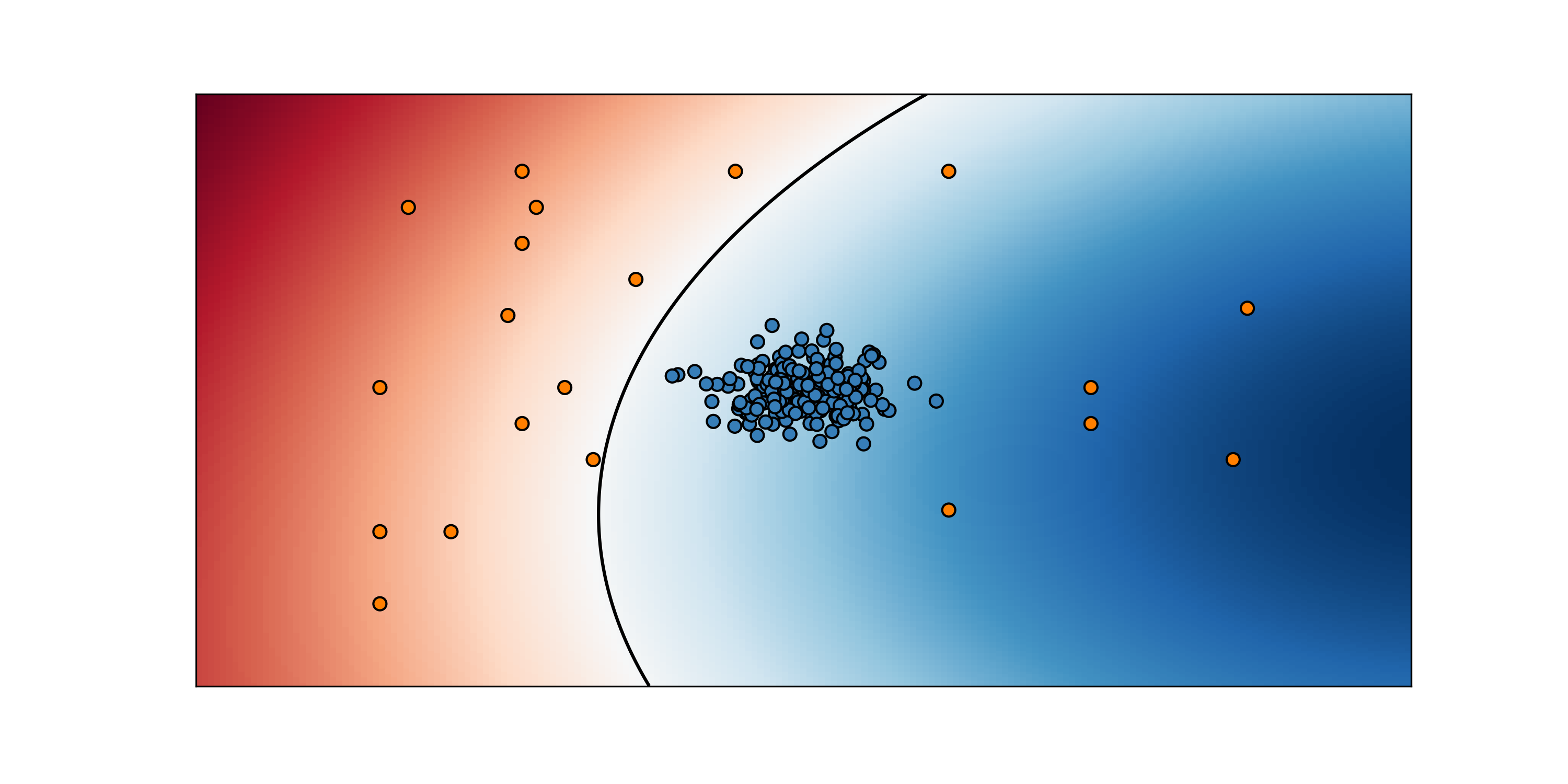
Auch! Our classifier is not doing so well… It turns out we can make a different kind of defective engine. In fact, this time all the faulty engines are in the bottom-right part of the map. We didn’t think of it… Does that mean that every time we discover a new kind of anomaly our classifier will make a wrong prediction? Well… What is it good for then? Let’s flush all that machine learning mambo jumbo down the drain. Hey hey, wait a sec! Why don’t go and try to do things differently? Let’s forget about anomalies for a moment and just try to learn what it means to be normal…
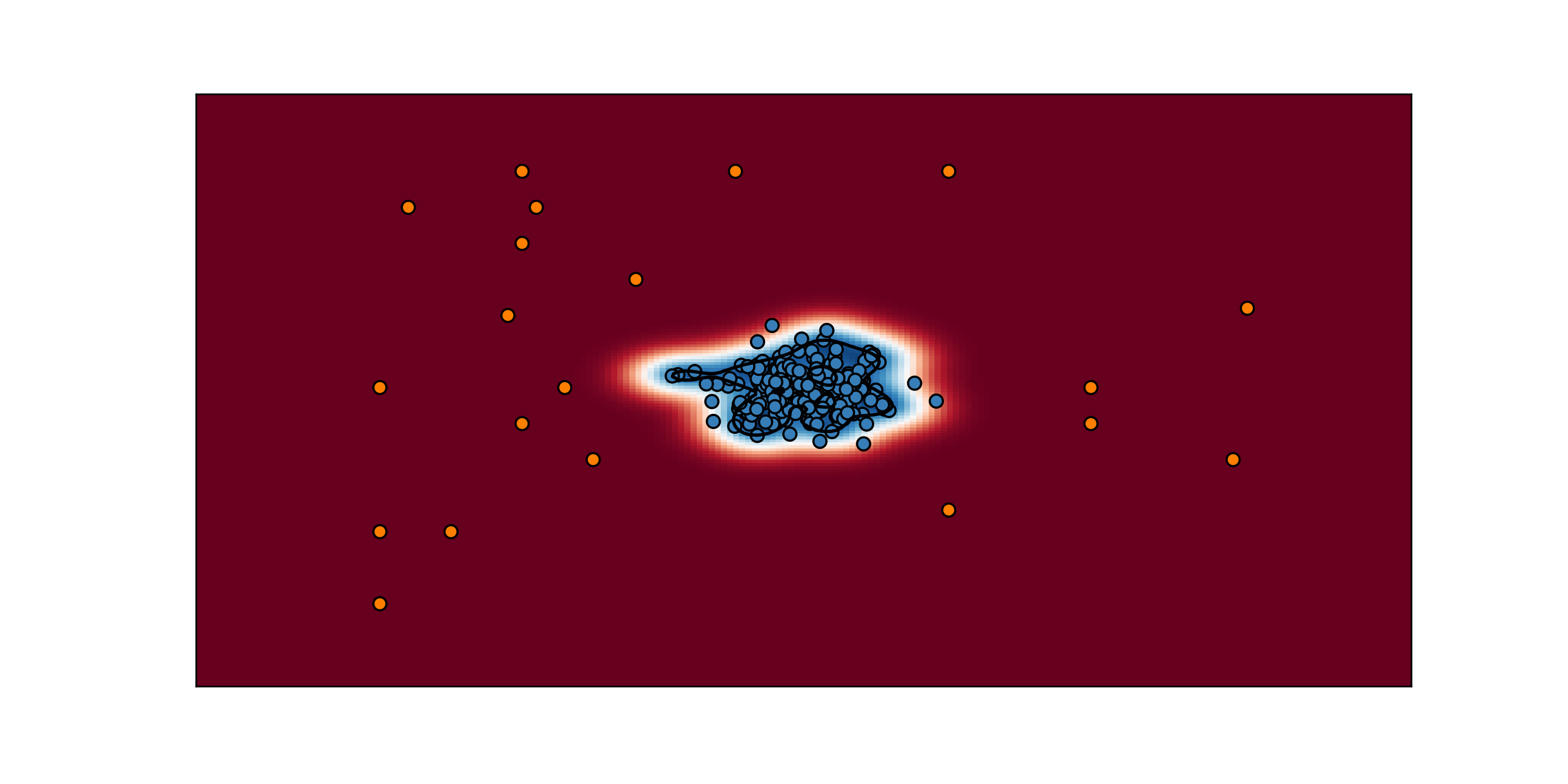
That seems better, right? How did I do it? Well, to tell the truth, I used One-Class SVM (no, I am not cheating I did not use the new kind of anomaly to train the model). It is an anomaly detection technique that just tries to model normal behavior without defining what an anomaly is.
But that calls for another story.
Take away:
Anomaly detection is not binary classification because our models do not explicitly model an anomaly. Instead, they learn to recognize only what it is to be normal. In fact, we could use binary classification if we had a lot of anomalies of all kinds to work with… But then, they wouldn’t be anomalies after all!
Stay tuned on flair-tech.com for the next episodes where we will dive into some anomaly detection techniques!
